|
I am a Computer Science Ph.D. student at IIT Gandhinagar, India, advised by Prof. Shanmuganathan Raman. My research interests include 3D computer vision, generative networks, graph neural networks, representation learning and brain-computer interface (BCI). Email / Google Scholar / GitHub / LinkedIn / Twitter / YoutTube / CV / Python Notes |
||
|
|
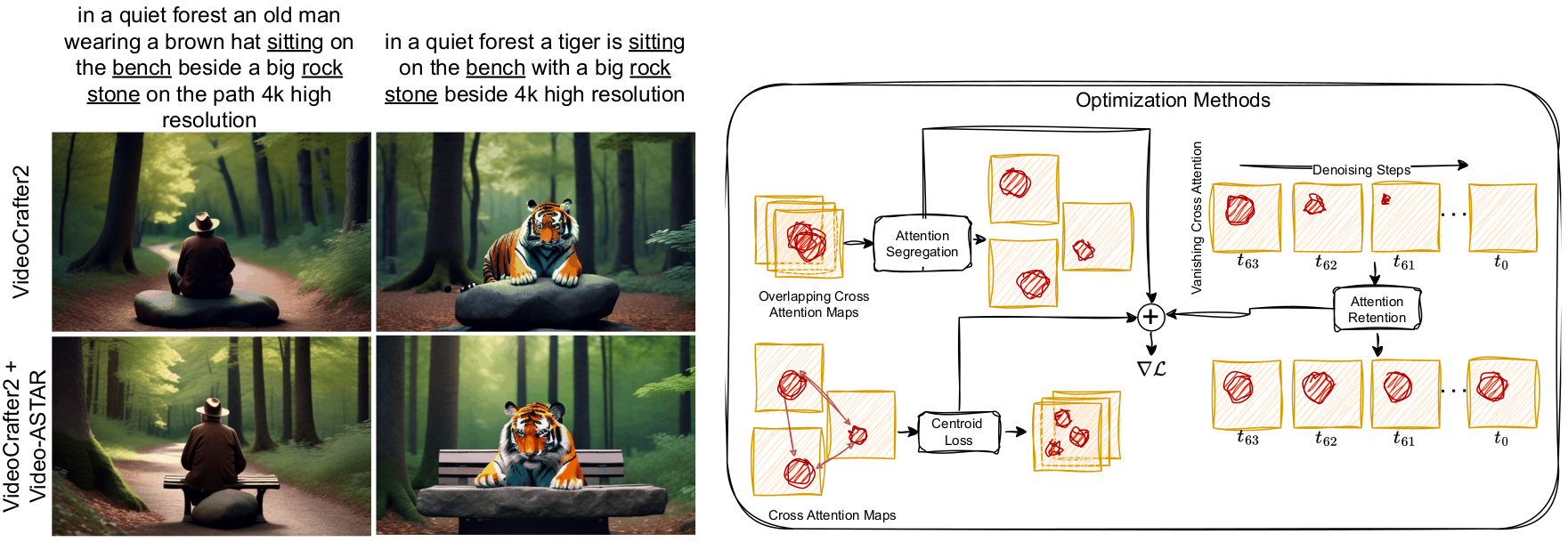
Prajwal Singh, Kuldeep Kulkarni, Shanmuganathan Raman, Harsh Rangwani,
WACV 2026
project page/ paper
This work tackles the challenge of compositional video generation from a text prompt by employing a straightforward, training-free method using a pre-trained video diffusion model. We have introduced Video-ASTAR with centroid loss for the optimization process over the cross-attention map. With comprehensive empirical results and ablation studies, we show its effectiveness over baselines.
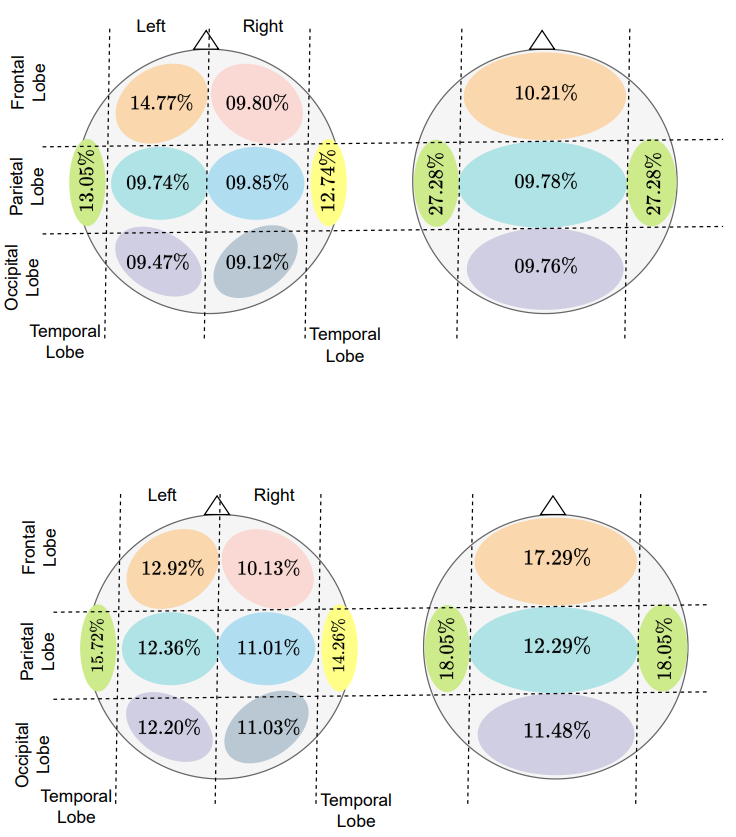
Prajwal Singh, Anupam Sharma, Pankaj Pandey, Krishna Miyapuram, Shanmuganathan Raman,
Arxiv
project page/ arXiv
In this work, we study the dynamic visual information encoded in EEG signals and demonstrate how it can be reconstructed using temporally conditioned generative modeling. Further, investigates whether EEG signals contain sufficient information for decoding continuous visual experiences.
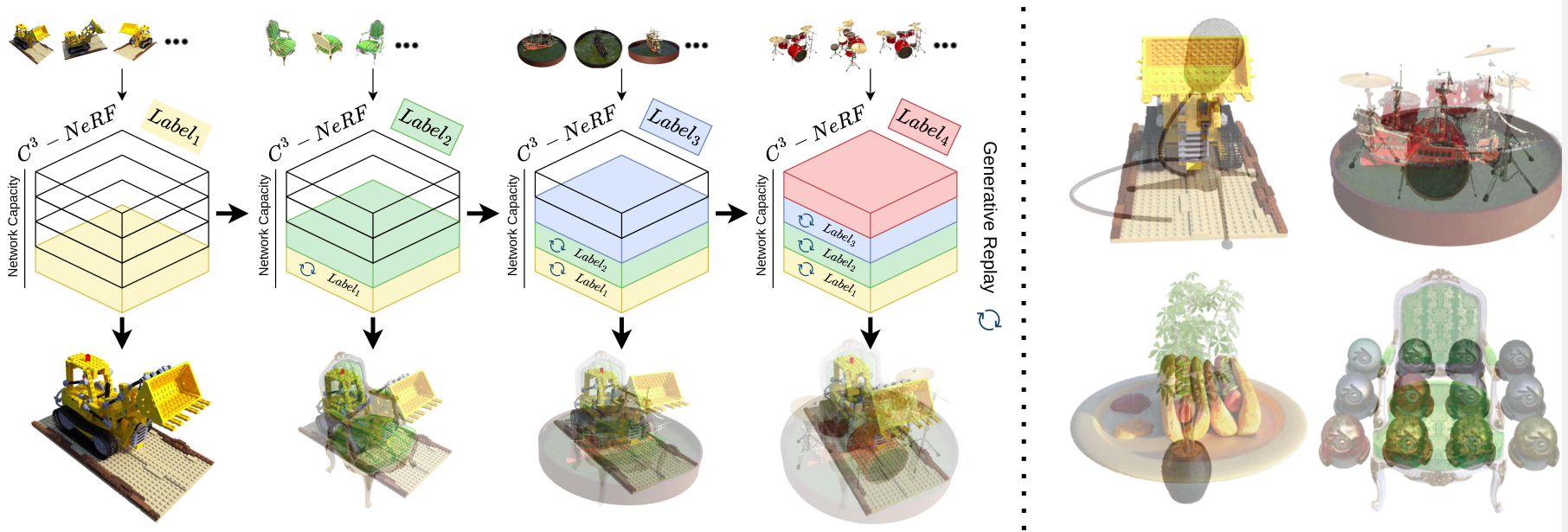
Prajwal Singh, Ashish Tiwari, Gautam Vashishtha, Shanmuganathan Raman,
BMVC 2025
project page/ arXiv
We introduce C-NGP, a scalable framework that encodes multiple 3D scenes into a single NeRF model using pseudo-scene labels for conditioning. It supports continual learning with minimal forgetting, enabling high-quality novel-view rendering across multiple scenes without additional parameters.
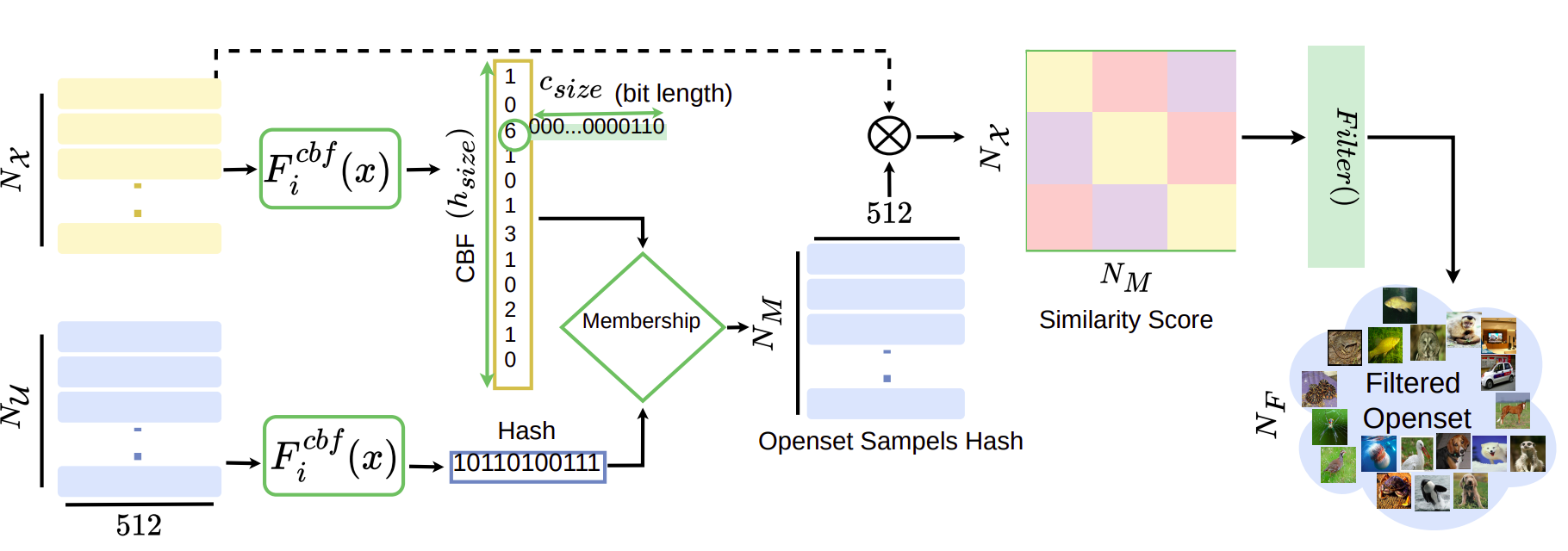
Prajwal Singh, Gautam Vashishtha, Indradeep Mastan, Shanmuganathan Raman
ICASSP 2025
project page/ arXiv
We present BloomCoreset, a novel method for efficient subset sampling in fine-grained Self-Supervised Learning (SSL). By leveraging Bloom filters for space-efficient storage and rapid retrieval of image features, BloomCoreset reduces sampling time from large unlabeled datasets (Open-Set) by 98.5%, with only a 0.83% accuracy trade-off on 11 downstream tasks. Integrated with the state-of-the-art SSL framework, SimCore, our approach significantly improves sampling efficiency while maintaining high-quality coreset performance.
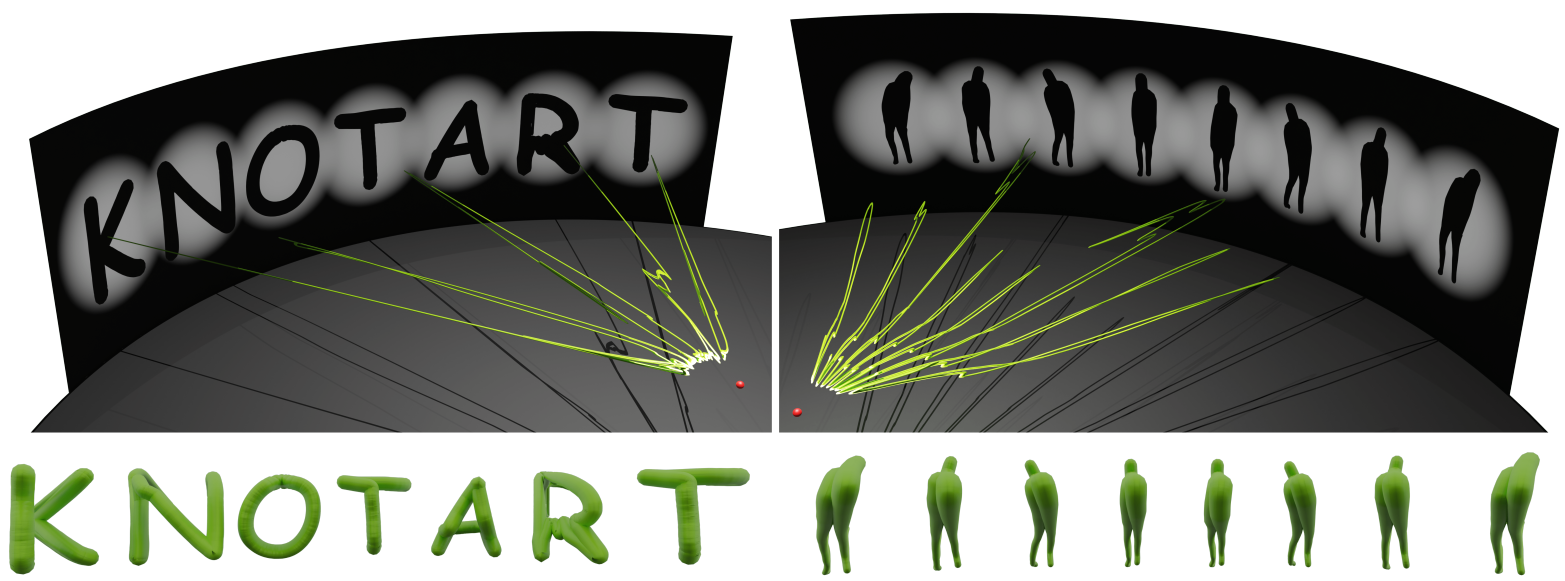
Aalok Gangopadhyay, Paras Gupta, Tarun Sharma, Prajwal Singh, Shanmuganathan Raman
Computer Graphics Forum / Symposium on Geometry Processing, 2024
project page/ arXiv
We propose a fully differentiable framework for designing 3D tubular knot structures that resemble target images from specific viewing angles. Using an invertible neural network and physically-constrained optimization, our method generates realistic and practical knot embeddings, validated through experiments, ablation studies, and a 3D-printed object.
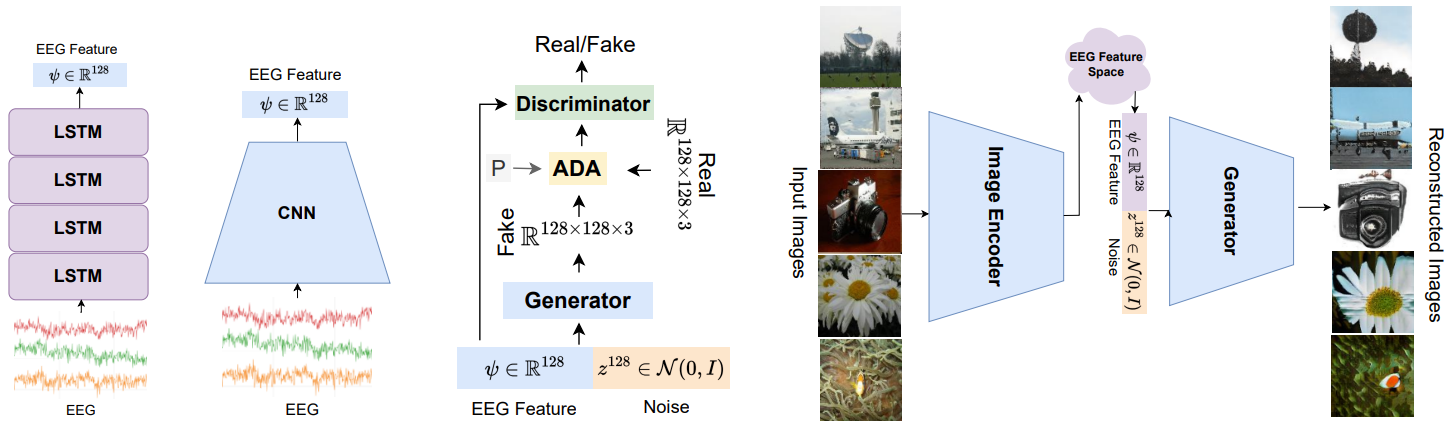
Prajwal Singh, Dwip Dalal, Gautam Vashishtha, Krishna Miyapuram, Shanmuganathan Raman,
WACV 2024 (featured in WACV Daily and Best of WACV 2024)
project page/ arXiv/ WACV Daily/ Best of WACV 2024
This study presents a two-stage method utilizing EEG-derived features for deep representation learning, demonstrating its generalizability across multiple datasets and achieving superior results in EEG-based image synthesis, including image reconstruction and classification tasks, outperforming existing GAN-based methods.
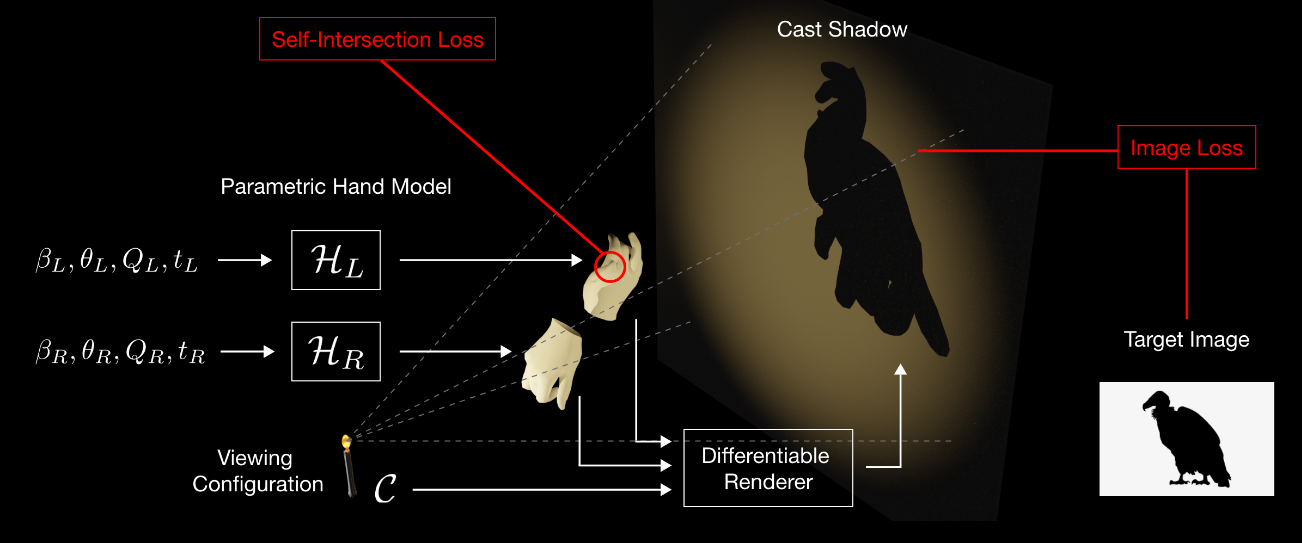
Aalok Gangopadhyay, Prajwal Singh, Ashish Tiwari, Shanmuganathan Raman,
Pacific Graphics: Poster, 2023 (Best Poster Award)
project page/ arXiv/ PG2023
This work introduces a novel approach using differentiable rendering to deform hand models, enabling the creation of meaningful and consistent shadows resembling desired target images.

Prajwal Singh, Ashish Tiwari, Kaustubh Sadekar, Shanmuganathan Raman,
Pacific Graphics: Poster, 2023
project page/ arXiv/ PG2023
This work proposes a tree-structured autoencoder framework to generate robust embeddings of point clouds by utilizing hierarchical information using graph convolution. We perform multiple experiments to assess the quality of embeddings generated by the proposed encoder architecture and visualize the t-SNE map to highlight its ability to distinguish between different object classes.
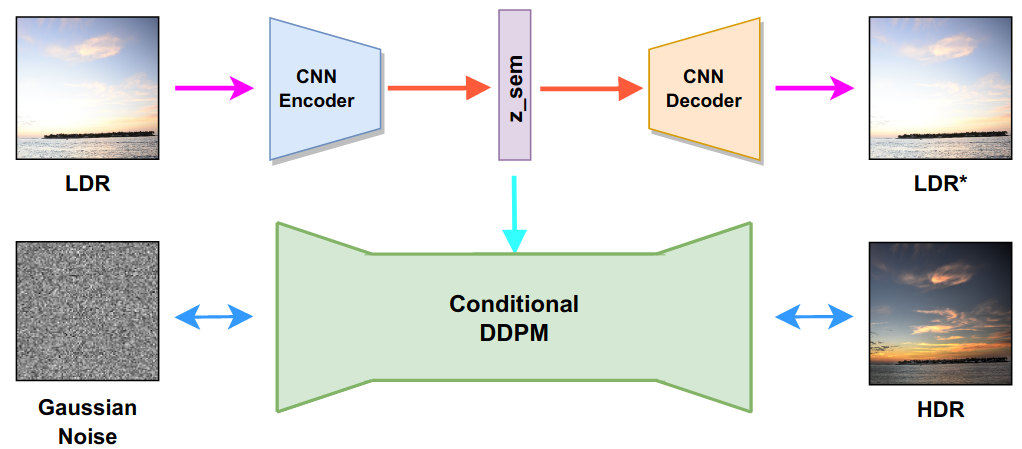
Dwip Dalal, Gautam Vashishtha, Prajwal Singh, Shanmuganathan Raman
ICIP, 2023
project page/ arXiv/ video
We formulate the problem as an image-to-image (I2I) translation task and propose a conditional Denoising Diffusion Probabilistic Model (DDPM) based framework using classifier-free guidance. We incorporate a deep CNN-based autoencoder in our proposed framework to enhance the quality of the latent representation of the input LDR image used for conditioning.
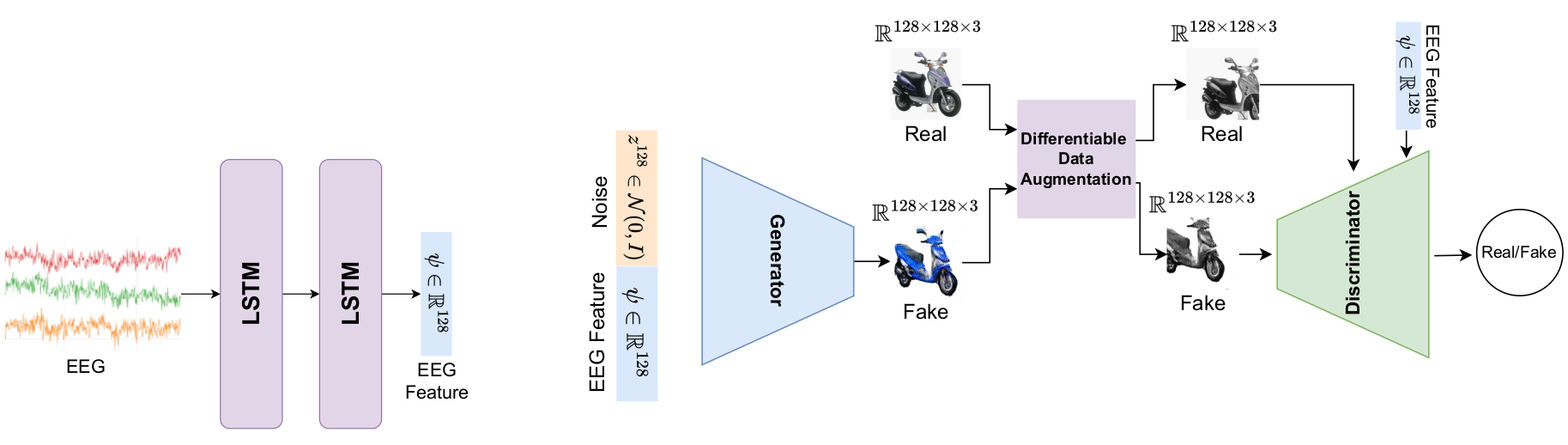
Prajwal Singh, Pankaj Pandey, Krishna Miyapuram, Shanmuganathan Raman
ICASSP, 2023
project page/ arXiv/ video
We use a contrastive learning method in the proposed framework to extract features from EEG signals and synthesize the images from extracted features using conditional GAN. We modify the loss function to train the GAN, which enables it to synthesize 128x128 images using a small number of images.
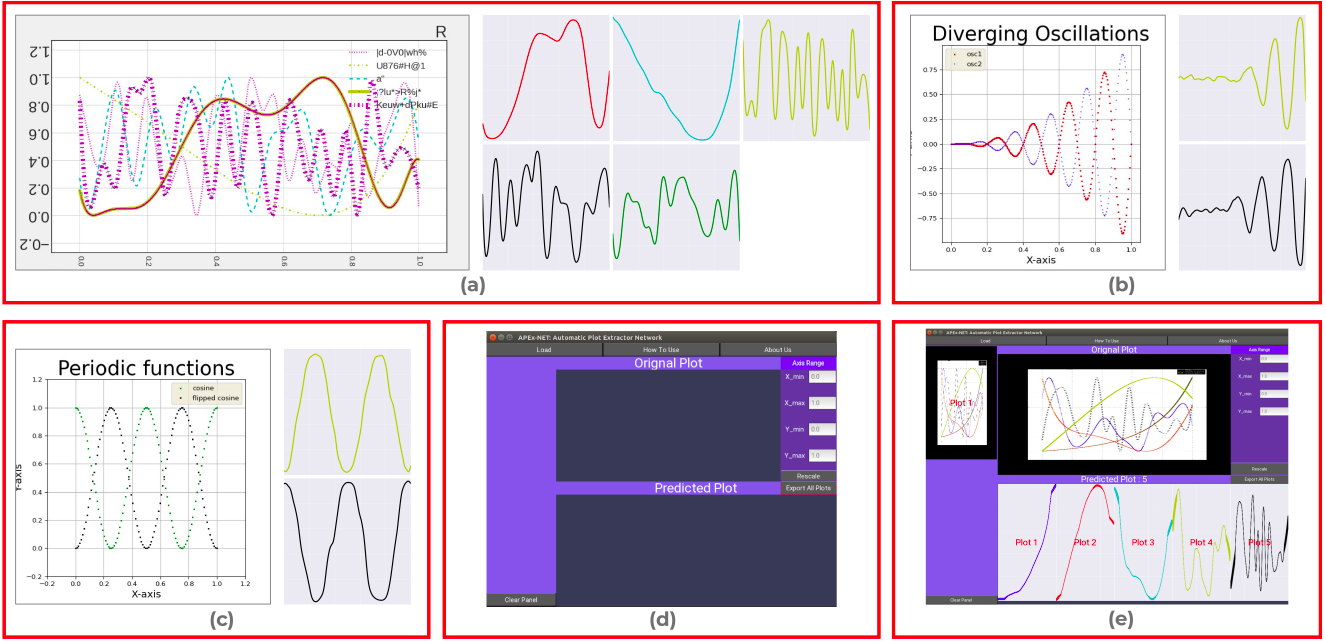
Aalok Gangopadhyay, Prajwal Singh, Shanmuganathan Raman
NCC, 2022
project page/ arXiv/ video
To minimize this intervention, we propose APEX-Net, a deep learning based framework with novel loss functions for solving the plot extraction problem. We introduce APEX-1M, a new large scale dataset which contains both the plot images and the raw data.
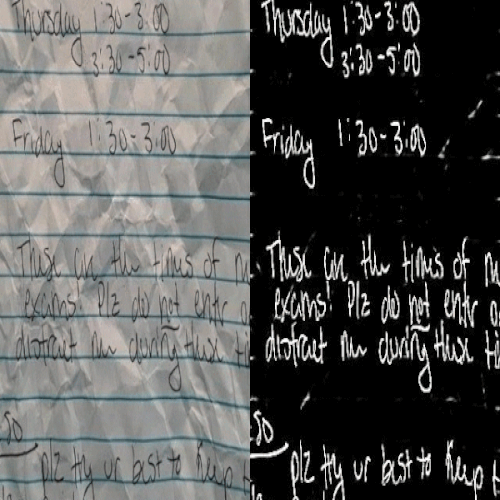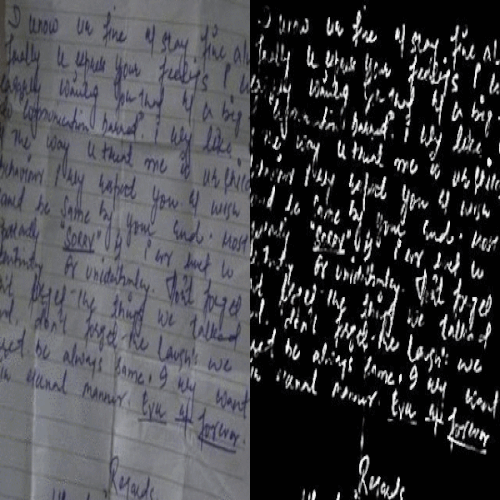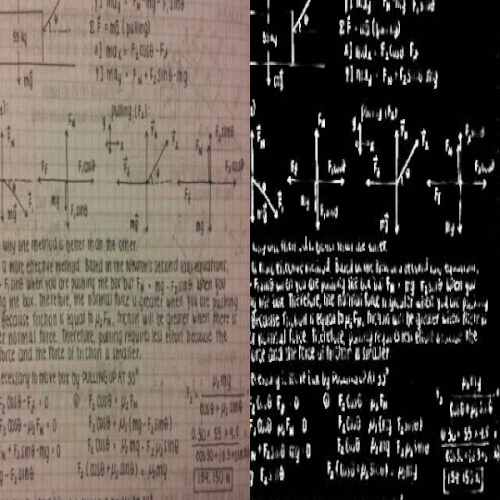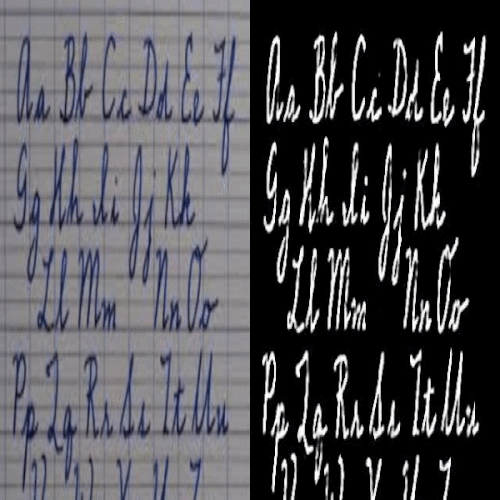
Kaustubh Sadekar, Ashish Tiwari, Prajwal Singh, Shanmuganathan Raman
ICPR, 2022
project page/ arXiv/ video
We propose a large scale dataset of 1 Million challenging images for the task of hand written document image binarisation (HDIB) with accurate segmentation groundtruth.
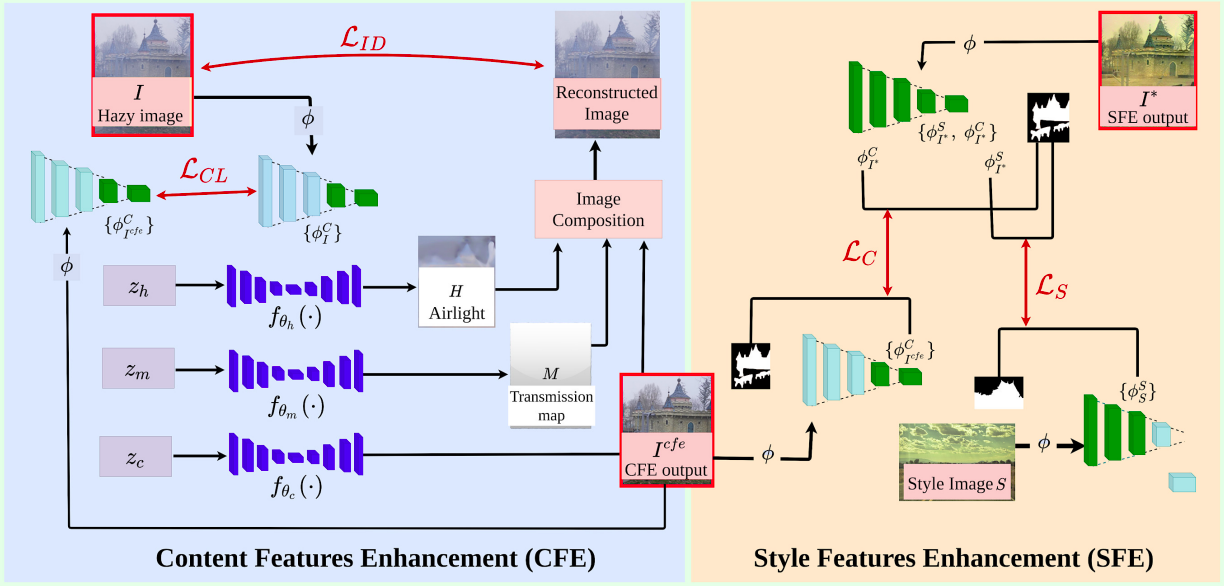
Indradeep Mastan, Shanmuganathan Raman, Prajwal Singh
WACV VAQ Workshop, 2022
project page/ arXiv/ video
We perform image enhancement using a deep internal learning framework. Our Deep Internal Learning for Image Enhancement framework (DILIE) enhances content features and style features and preserves semantics in the enhanced image.
|
Thanks to Jon Barron for this awesome template and Pratul Srinivasan for additional formatting. |